Clustering Overview
Loadcoder can be clustered over several remote servers. The main idea behind this is that you can distibute your load test over more resources than you would have in you own workstation. This will be important if you design tests that uses a lot of CPU and memory. Since Loadcoder measures response times, it is crucial that enough resources always is available throughout the execution.
Architecture

Description
The cluster can be setup in a various of ways but the underlying technique is the same. The cluster infrastructure is managed as code with a Controller application that calls the Docker API at each node. You can customize how many Loadcoder instance you would like, which docker image versions to use and of course where the cluster shall execute. See below list to get a more detailed description:
The Workstation
This is typically your computer where you have your IDE and develop the tests. You will also manage the cluster from here
The Master and the Workers
The Master and the Worker nodes will be machines runnning Linux with the Docker API running. Follow instructions for Initial Cluster Setup to setup these machines.
Controller
The Controller is a Java application you use from your workstation to manage you Loadcoder cluster. You can for instance setup the entire cluster, start a performance test and tear the test down, fully automated, with just a few lines of code. Follow the Controller instructions for how to create and use it.
Loadcoder
The cluster are distributing Loadcoder instances as Docker containers through the Docker API. Check out the Loadcoder container description for further information.
Host volume
Host volume is a persistent volume shared between the host machine and the Loadcoder container. Read the Host volume description for more information.
Deployment
This section describes different ways deploying the cluster
If your clustered Loadcoder test doesn't work as expected, please consult the Troubleshooting section
Run entire cluster at your Workstation
It is possible to run the entire cluster locally at your Workstation. This deployment is recommended for early performance tests and as a good first step to understand how the Loadcoder cluster works.
Keep in mind that your workstation will run both the Master and the Worker containers on top of everything else that is running. Be therefore aware of the amount of resources being used.
- Make sure your Workstation are setup both as a Master and Worker, according to Initial Cluster Setup
- Create a Load Test project and configure you Workstation as the single node.
Run entire cluster at a remote machine
- Make sure the inteded machine are setup both as a Master and Worker, according to Initial Cluster Setup
- Create a Load Test project and configure you the remote machine as the single node.
Run cluster distributed on several remote machines
- Make sure the intended machines are setup both as a Master and Worker, according to Initial Cluster Setup
- Create a Load Test project and configure all machines as nodes. Choose one of them to be the Master node.
Initial Cluster Setup
This section describes how the setup the prerequisites at the Master and Worker nodes

You need to keep attention to the security before setting up the cluster. Consider the security measures listed at the Cluster Security page to stay safe!
System Requirements
These are the recommended lowest specs needed to setup a machine:
All machines needs to be able reach the Master node over the network
Master specific
- Storage: 40 GB
- RAM: 8 GB
Worker
- Storage: 15 GB
OS
As of today, Loadcoder Cluster needs to be executed at Linux. The Following list are Linux distributions and verions that has been verified to be able to execute the cluster
- Ubuntu 18.04
Domain lookup
While not required, it is recommended to use machines that can be identified by host through a DNS that all the nodes (including the workstation) can reach. Using DNS hosts will simplify the cluster infrastructure configuration, that oterwise needs to be done by using local host to IP mappings. See the cluster configuration page for more details on how to configure the cluster infrastructure.
If your cluster machines can't be found through a DNS, you can setup local host / ip lookup manually. In Linux this is done in the file /etc/hosts. In this case, add the host / ip mappings at all the machines in you cluster like below:
192.168.1.100 masternode
192.168.1.101 workernode1Docker API
The Docker API is a service that takes request and performs docker operations. Edit the following file:
$ vi /lib/systemd/system/docker.serviceComment out or remove the following line with a # like this:
# ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sockPaste the following line after the line above. Note that since the Docker API will be setup using an unsecure connection, it is cruical that you use nothing else but the IP 127.0.0.1 here. This will only work if you run the entire cluster at one machine (your Workstation). If you want to distribute your cluster over remove machines, it is highly recommended to setup the Docker API with MTLS according to the Cluster Security instructions
ExecStart=/usr/bin/dockerd -H fd:// -H tcp://127.0.0.1:2375Then execute the following commands to active the Docker API
$ systemctl daemon-reload
$ service docker stop
$ service docker start
Verify that the port up and listening on ip 127.0.0.1:2375
$ netstat -an | grep 2375
tcp 0 0 127.0.0.1:2375 0.0.0.0:* LISTENThe Load Test project
This section describes how to build each cluster related component of your load test project.

Instead of starting from scratch, you can always use the Loadcoder examples zip below. It contains some useful examples for how to start building your own clustered Load Test project from.
 loadcoder-examples.zip
loadcoder-examples.zip
Controller
The Controller is a Java application that you will use to manage the Loadcoder cluster. There is no GUI. Everything is done through code and configuration. Below is an examle of a Controller app.
import java.io.File;
import com.loadcoder.cluster.clients.grafana.GrafanaClient;
import com.loadcoder.cluster.clients.docker.LoadcoderCluster;
import static com.loadcoder.cluster.clients.docker.MasterContainers.*;
public class Controller {
public static void main(String[] args){
LoadcoderCluster cluster = new LoadcoderCluster();
//Creates and starts Grafana, InfluxDB, Loadship and also Artifactory
cluster.setupMaster();
//Send this Maven project as a zip file to the Loadship server
//cluster.uploadTest(new File("."));
//Start a new clustered Loadcoder test
//cluster.startNewExecution(1);
//Create a Grafana Dashboard based on the data that the test wrote to InfluxDB
//GrafanaClient grafana = cluster.getGrafanaClient(cluster.getInfluxDBClient("LoadcoderClusterTests", "InfluxReportTest"));
//grafana.createGrafanaDashboard();
//Stops and removes Grafana, InfluxDB and Loadship
//cluster.stopExecution();
}
}loadcoder.conf
loadcoder.conf is the default configuration file that Loadcoder will try to find as a resource
Below is a minimal configuration file that will will work when running the cluster locally (at your Workstation). The configuration file can be extended with customized ports, additional nodes. Visit the Cluster Configuration Documentation for the full description.
Also note that a hostip mapping is configured and used as the host value for the master host. In order to make it work, the hostname master must be resolvable from the Workstation, either by DNS or by adding it into the file /etc/hosts
Note that docker.mtls below is set to false, which is unsecure. MTLS shall only be disabled in situations where the Docker API can't be reached by anyone else. If you remove this parameter, or set the value to true, the Docker client will try to authenticate with mtls. See Cluster Security for information of how to setup MTLS.
################## CONTAINERS ##################
influxdb.image=influxdb:1.7.10
grafana.image=grafana/grafana:5.4.3
loadship.image=loadcoderhub/loadcoder:1.0.0
loadcoder.image=loadcoderhub/loadcoder:1.0.0
################ INFRASTRUCTURE ################
cluster.masternode=1
docker.mtls=false
node.1.host=master
node.1.dockerapi.port=2375
hostip.master=192.168.1.104test.sh
test.sh is a required file that must exist in order for your test to work. It is a bash script that will be executed inside each Loadcoder container that you start.
This is where you decide how the actual Loadcoder test command shall be executed. The recommeded way is to run the test in the Maven test phase, like shown below.
Be creative! Design you script as you want it.
#!/bin/bash
echo "Create this test script however you like it!"
mvn -Dtest=MyLoadTest -Dloadcoder.configuration=cluster_configuration.conf test > /root/host-volume/$LOADCODER_CLUSTER_INSTANCE_ID.log Loadcoder Test
If implemented correctly, Loadcoder tests will run just as good locally as within the cluster. This is true for everything except that is cluster you not have access to a display. This means that you cannot use the RuntimeChart or ResultChart graphs as they are GUI components that will try to start inside the clustered docker container. This wont work!
Instead, use the InfluxDB and Grafana integration to show your Loadcoder results. The example below shows how to call the method storeAndConsumeResultRuntime so that all results are reported runtime into the InfluxDB database configured in you loadcoder configuration file
import org.testng.annotations.Test;
import com.loadcoder.cluster.clients.docker.LoadcoderCluster;
import com.loadcoder.cluster.clients.influxdb.InfluxDBClient;
import com.loadcoder.load.LoadUtility;
import com.loadcoder.load.scenario.ExecutionBuilder;
import com.loadcoder.load.scenario.Load;
import com.loadcoder.load.scenario.LoadBuilder;
import com.loadcoder.load.scenario.LoadScenario;
import static com.loadcoder.statics.Statics.*;
public class InfluxReportTest {
@Test
public void influxReporterTest() {
LoadScenario ls = new LoadScenario() {
@Override
public void loadScenario() {
load("simple-transaction", () -> { LoadUtility.sleep(54);
}).perform();
}
};
Load l = new LoadBuilder(ls)
.stopDecision(duration(120 * SECOND))
.throttle(2, PER_SECOND, SHARED).build();
//THIS IS WHERE YOU IMPLEMENT HOW THE LOADCODER TEST REPORTS THE RESULT TO THE INFLUXDB.
new ExecutionBuilder(l)
.storeAndConsumeResultRuntime(InfluxDBClient
.setupInfluxDataConsumer(new LoadcoderCluster(), "LoadcoderClusterTests", "InfluxReportTest"))
.build().execute().andWait();
}
}The zip
The distribution of the test is made by zipping the Load test project and then send it to the Loadship container. The Loadship will store it in memory and make it available for download. The containers that will run Loadcoder will start by downloading and unzipping the the Load test project from Loadship and then execute test.sh
Maven Configuration
If your load test project depends on other artifacts managed at your local Maven repository, the Maven settings needs to be configured accordingly. This can be done in two approaches.
Using existing Maven repository
If you already have a Maven repository at hand that you want to use for you load tests, you will have to configure Maven in the Loadcoder container. The way you do this is by adding a copy of the Maven configuration file settings.xml in the load test project. Adjust the copy of the settings.xml according to below guidance:

The default path to Maven configuration file in Linux would be the following. Copy this file to your load test project
/usr/share/maven/conf/settings.xml This file needs to be adjusted so that the Maven execution will work inside the Loadcoder container. See step 5 and 6.
Before the maven command that starts your test is executed, the settings.xml needs to be copied inside the container. This is done by adding a copy command to the test.sh script. Below is an example of a test.sh file where the copy is taking place:
#!/bin/bash cp settings.xml /usr/share/maven/conf/settings.xml mvn -Dtest=MyLoadTest test > /root/host-volume/$LOADCODER_CLUSTER_INSTANCE_ID.log - When starting clustered test, the Load test project will sent over (through Loadship) to the node where the Loadcoder container executes
- The test.sh copies the settings.xml to the Maven configuration directory inside the container
The value for localRepository defines where Maven will store the downloaded artifacts. It is recommended to store them at the Host volume. By doing so, they will be kept between executions, giving a faster starting time.
<localRepository>/root/host-volume/mvn-repo</localRepository> The repository and server configuration needs to be set according to your Maven repository. If the load test project is possible to build at the Workstation using the settings.xml that was copied, it will probably work without futher adjustments
CAUTION! Be careful what information you set in this file and how you store it. Maven settings.xml could contain passwords not meant to be shared
-
Setting up a new local Maven repository
If you don't have a local Maven repo you can setup a new one, in the same fashion you setup the applications on the Master node, through the Contoller.
Follow the JFrog Artifactory instructions to set it up.
The Loadcoder container will default include Maven configuration, expecting Artifactory repo to be present at the hostname master. If you add the master as hostip mapping in the loadcoder.conf file, and setting up the Artifactory with the same user credentials stated in the instruction, you need to add the settings.xml to your load test project like described above
Loadcoder Container
The Loadcoder load test will be distributed to the Worker nodes through the Docker API. Each instance will run inside a container built with the image loadcoderhub/loadcoder. It will download the test package earlier uploaded to the Loadship service and execute the test.sh.
The image comes with the below applications at hand for your load test execution
- Java openjdk version "11.0.6" 2020-01-14
- Apache Maven 3.6.3
Host volume
The host volume is a storage volume that can both be accessed from the host machine as well as from inside the Loadcoder container. It is created during the creating of the Loadcoder container and the content will be persisted even though the containers are deleted. The Host volume will be used to persist logs and the Maven local repository by default, but can be used as you like for other things as well. The volume is mounted inside the Loadcoder container at:
/root/host-volume By using the docker inspect command with the loadcoder container ID and grep for "Source" you can find where to volume is mounted on the host machine:
$ docker inspect 8313f0b2e9c1 | grep Source
"Source": "/var/lib/docker/volumes/LoadcoderVolume/_data", If you redirect the output from the command that starts the test to a log file at the host volume (as shown in test.sh), you have an easy way of accessing the test output from the machine where the container is running
Grafana & InfluxDB
Grafana is a webservice for data visualization. InfluxDB is a time series database. Together they compose the reporting mechanism of the Loadcoder Cluster. It works like this

- When a Loadcoder test is started with the InfluxDB reporting mechanism, it will first make sure that there is database within InfluxDB that has the name that corresponds to the group name and the test name stated in the call InfluxDBClient.setupInfluxDataConsumer
If the database doesn't exist it will be created. The the test starts and Loadcoder will continuously report the transaction results to InfluxDB throughout the test.new ExecutionBuilder(load).storeAndConsumeResultRuntime( InfluxDBClient.setupInfluxDataConsumer(new LoadcoderCluster(), "LoadcoderClusterTests", "InfluxReportTest")) .build().execute().andWait(); - When test test successfully started, a Grafana Dashboad can be created that shows the results. This can be done from the Controller class by calling the GrafanHelper
The group name and the test name is here reuse, as well as a regexp pattern to match the exeuction id of the test. If not specified otherwise, this will be a String containing date and time. The first thing that happens is that InfluxDB will be called to find the transactions that are reported in by the test. The purpose is this is to find the transaction names. It is therefore important that the load test is started and already reported results for each transaction name before the dashboard is created.LoadcoderCluster client = new LoadcoderCluster(); GrafanaClient grafana = client.getGrafanaClient( client.getInfluxDBClient("LoadcoderClusterTests", "InfluxReportTest")); grafana.createGrafanaDashboard("2020.*"); - Once the information about the transaction have been collected from the database, Grafana is called to create the datasource and the dashboard.
- The dashboard can be viewed by login in to the Grafana web (http://localhost:3000 if running Grafana at localhost and default port. Default user and password is admin / admin). Go do Dashboard -> Manage to find the dashboard grouped up as directories with names accoring to the group name you used during creation
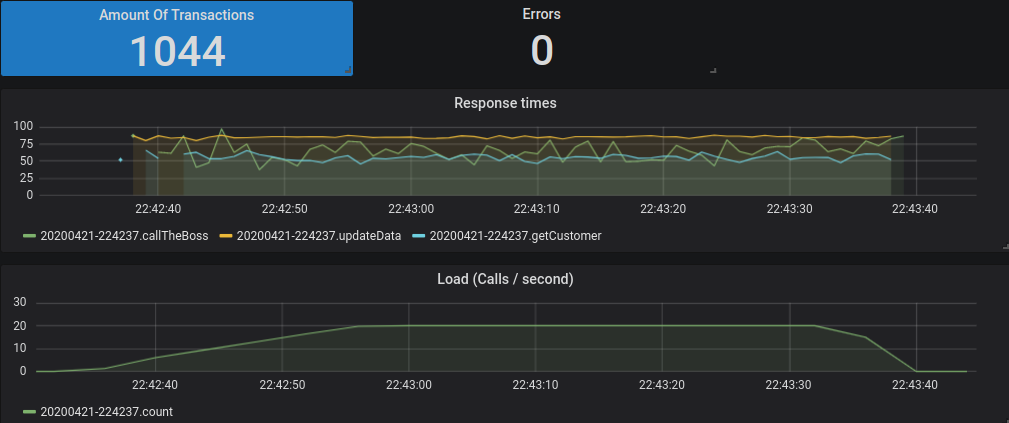
You can easily create new graphs for your load tests by using the GrafanaHelper
Offline mode
A Loadcoder cluster can partly be used offline (without access to internet). This sections explains how

Running the cluster in offline mode is done by letting the Master and the Worker nodes access the required online service through a dedicated machine, described below as the Internet Accessor. Clustered Loadcoder tests needs internet access because of two reasons
Maven Dependencies
Loadcoder uses Maven for package management. When starting a Loadcoder container instance, Maven will try to download the load test project defined dependencies from the configured repository. This will be the online Central Maven repository by default
Docker images
The cluster consists of applications running in Docker containers. These containers are built from images that can be downloaded from the online service Dockerhub.
The Internet Accessor
There may be good reasons to not connect the cluster nodes to the internet directly. By introducing an Internet Accessor node, you will keep your cluster offline as well as functioning. This Internet Accessor can be any machine (even the Master node) that can be reached from the Master and the Worker nodes, and will run one local Maven repository and one Docker registy
Maven Repository
If you already have an established Maven repository with internet access, it is recommended to use that for distribution of the packages you need in you load tests.
Docker registry
You can setup a local Docker registry so that your cluster won't need access to the online repos directory. The images you need can be first pulled down to you local repo and then be download from the cluster containers. This is how to setup a local Docker repository
Create a certificate
First identify the hostname of the machine you will run the Docker registry on. This hostname will be used as a reference to lookup the images from the cluster containers. In similarity to the cluster nodes, its also recommended to be able to resolve the address to the Internet Accessor from a DNS, rather than to do it by local hostnames settings as it will require additional configuration.
Execute the following two commands to create a working directory for the certification creation
$ mkdir -p my-docker-registy/certs $ cd my-docker-registy Now execute the following command. It will prompt you with a list of questions. When propmted for the Common Name, answer with the hostname of the Internet Accessor you earlier identified
$ openssl req -newkey rsa:4096 -nodes -sha256 -keyout certs/domain.key \ -x509 -days 365 -out certs/domain.crt Place the certificate correctlty
You will now have 2 files inside the certs directory.
Now create a new directory with the same name as the hostname you used as Common Name to create the cert in the previous step
$ mkdir -p /etc/docker/certs.d/<hostname for the Internet Accessor> Place the certificate in that directory
$ cp certs/domain.crt /etc/docker/certs.d/<hostname for the Internet Accessor> Create and start the Docker registy
You will now have 2 files inside the certs directory.
Now create a new directory with the same name as the hostname you used as Common Name to create the cert in the previous step
$ docker run -d --restart=always --name registry_test1 -v "$(pwd)"/certs:/certs \ -e REGISTRY_STORAGE_DELETE_ENABLED=true -e REGISTRY_HTTP_ADDR=0.0.0.0:443 \ -e REGISTRY_HTTP_TLS_CERTIFICATE=/certs/domain.crt \ -e REGISTRY_HTTP_TLS_KEY=/certs/domain.key -p 443:443 registry:2 Using the local Docker registry
Before you use the local registy to download images from, you need to pull them down from the DockerHub. See the list of Master Containers for which images you need to setup the cluster as described. Execte the following for each of the images you need:
First pull down the image
$ docker pull influxdb:1.7.10 Then tag the image so that it starts with the Internet Accessor hostname
$ docker image tag influxdb:1.7.10 my-internetaccessor.com/influxdb:1.7.10 The image is now available to be downloaded from the cluster. Use the new tag in the loadcoder configuration file to speficy that the images shall be downloaded from the local Docker registry
influxdb.image=my-internetaccessor.com/influxdb:1.7.10